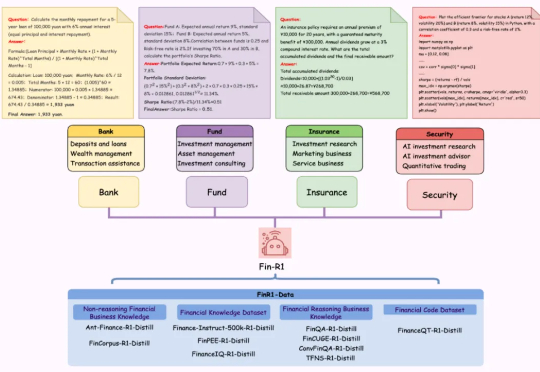
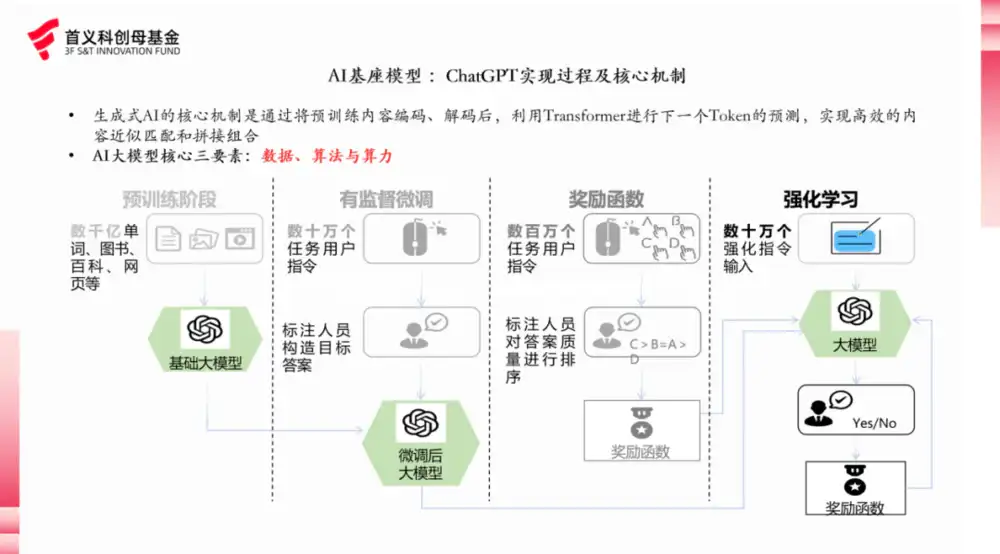
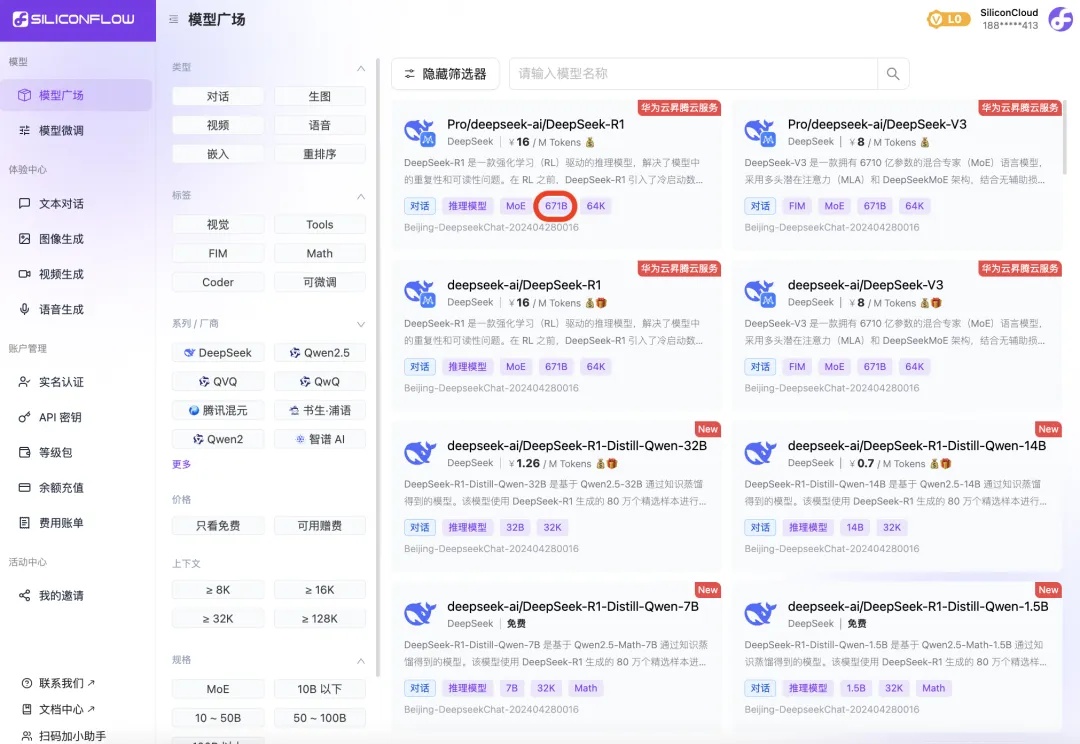
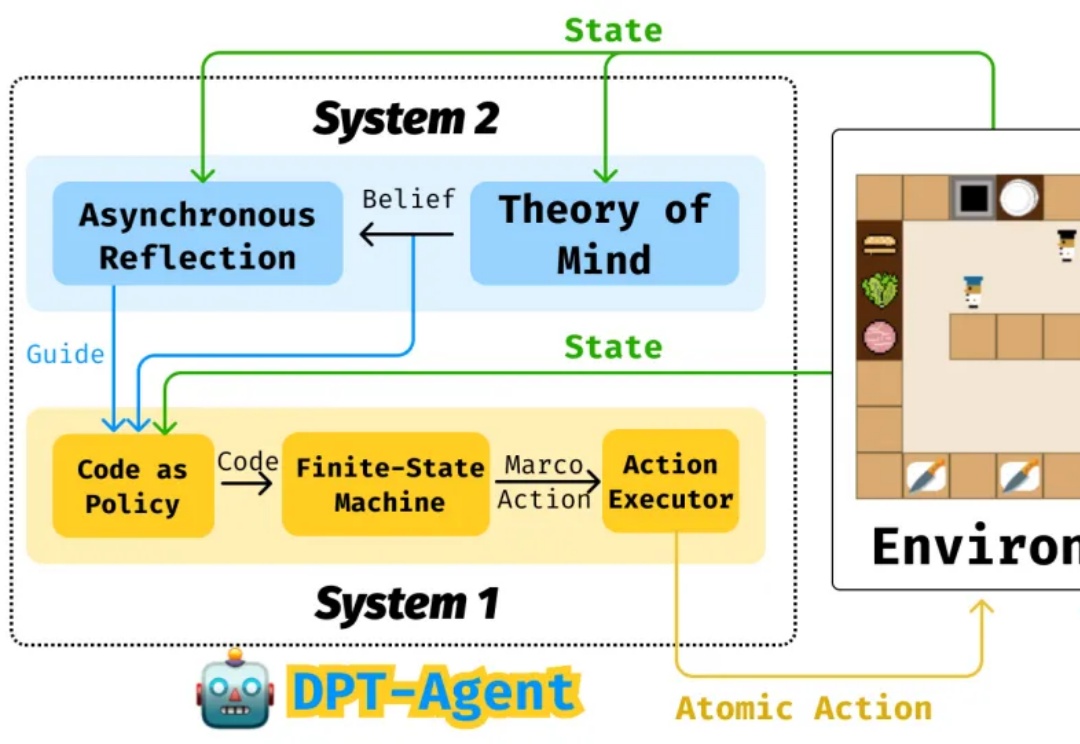
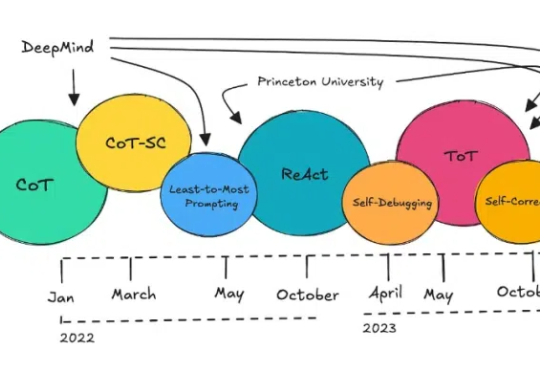
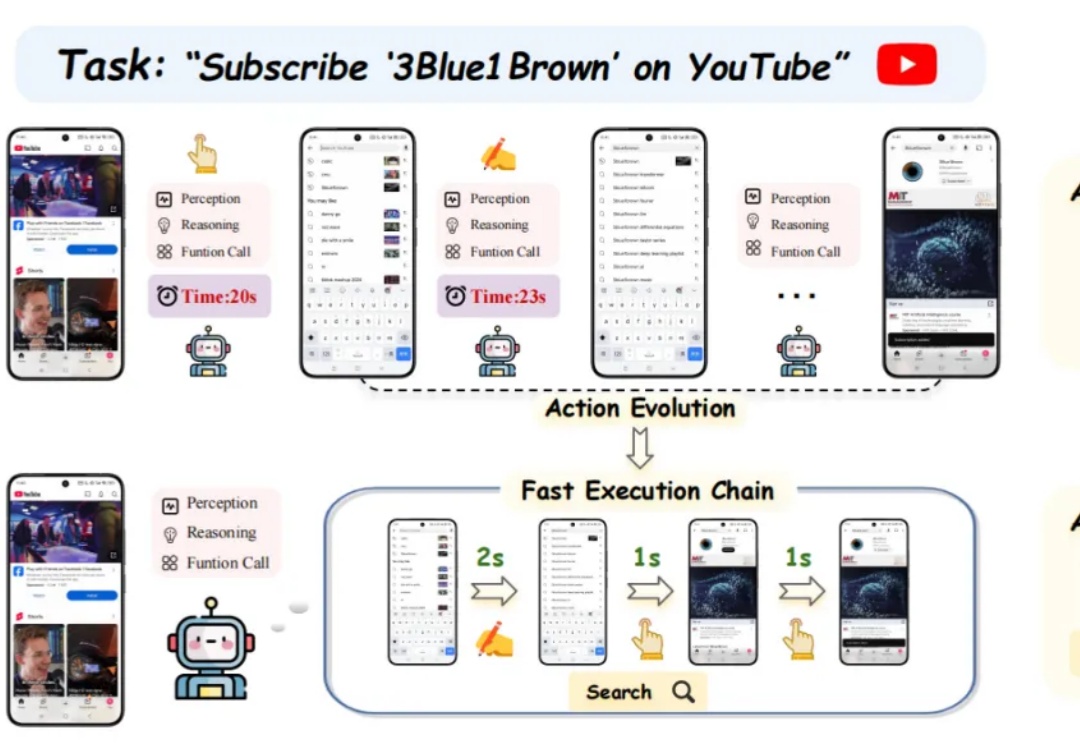
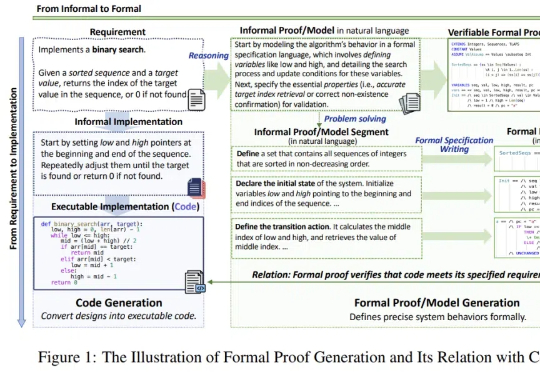
与真格戴雨森聊 Agent:各行业都会遭遇 “李世石时刻”,Attention is not all you need
与真格戴雨森聊 Agent:各行业都会遭遇 “李世石时刻”,Attention is not all you need晚点:过去将近 6 个月,AI 领域最重要的两件事,一是 OpenAI 去年 9 月 o1 发布,另一个是近期 DeepSeek 在发布 R1 后掀起全民狂潮。我们可以从这两个事儿开始聊。你怎么看 o1 和 R1 分别的意义?
来自主题: AI资讯
10257 点击 2025-03-29 00:33